

Why Your Multilingual AI Sounds Right and Still Gets It Wrong
Localization engineer Julia Diez on the semantic governance gap quietly costing global brands.


TL;DR: Multilingual AI sounds fluent and is often quietly wrong. LLMs reason in English even when writing in French or Japanese, with accuracy drops of up to 29 percent in non-English queries. Localization engineer Julia Diez calls the structural fix semantic governance: a multilingual product ontology, market-availability data, and Market DNA definitions that travel with every generation request.

I’ve been a quiet reader of Julia | Taking you global’s work for a while. She’s a Senior Localization Engineer and the founder of Black Ice, a semantic governance platform for multilingual AI pipelines, and she writes about a category of AI failure that doesn’t show up in any demo... the kind that sounds right.
Most of the leaders I coach run their AI in English (though my native language and dreaming language is Spanish). So do I, across all four of my businesses. That makes it easy to assume “fluent” and “accurate” are the same thing, because in English, they almost are. The minute you ship that same AI into Tokyo, Munich, or São Paulo, that assumption starts to cost you, and you don’t see it. The customer who tries to use a feature you don’t actually offer in their market doesn’t write a support ticket. They quietly leave.
What I respect about Julia’s framing is how unromantic it is. This isn’t a fear post. It isn’t an AI utopia post. It’s an engineer telling you, plainly, that fluency is a confidence problem and that the fix is structural. (For the leaders I work with on setting up AI context the right way, this is the multilingual extension of the same idea: the model doesn’t know your business unless you tell it. It also doesn’t know your market.)

I’ll get out of the way. Julia, the floor is yours.
The silent failure mode costing global brands more than they know
I’m Julia | Taking you global, a Senior Localization Engineer, and the founder of Black Ice, a semantic governance platform for multilingual AI pipelines. I’ve spent most of my career at the intersection of language, knowledge architecture, and AI. The problem I write about is one I’ve watched cause quiet, expensive damage at organisations that believed they had it solved.
There is a specific kind of AI failure that doesn’t announce itself.
The sentences look correct. The language is fluent. A native speaker might read the output and not catch anything wrong… Until a customer in Germany reads that a feature is available, tries to use it, and discovers it isn’t. Or until someone in Japan reads a product description calibrated for an American communication style and finds it, at best, oddly aggressive. Or until a legal team notices your AI has been using a competitor’s terminology in your own support content for months.
These aren’t hallucinations. The model isn’t fabricating facts from nothing. These are semantic governance failures, and they’re harder to catch precisely because the output looks right.
Most organisations deploying AI across multiple markets are producing them right now, at scale, without knowing it.
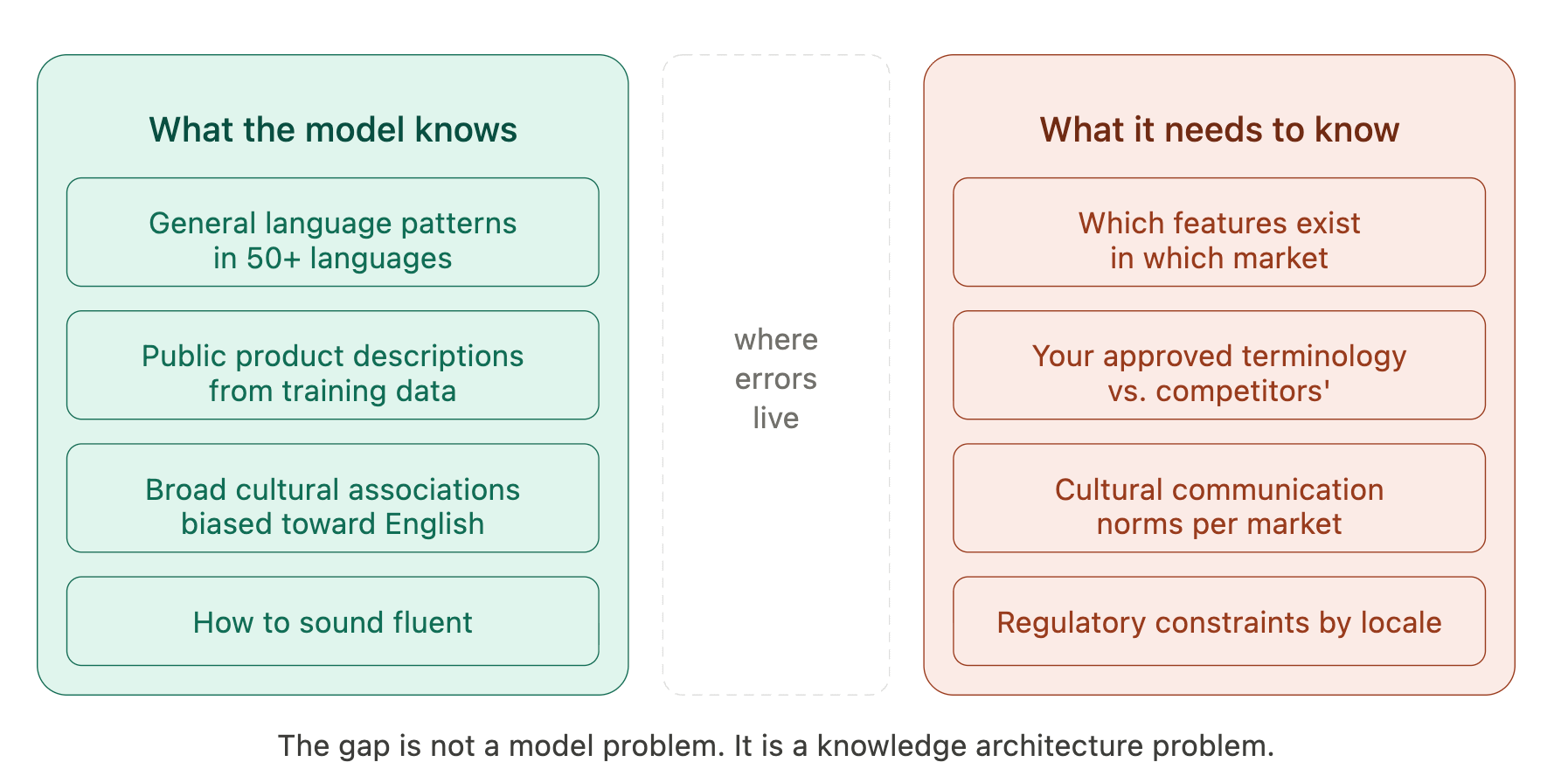
Why Fluency and Correctness Are Not the Same Thing
Modern large language models can generate text in dozens of languages at a quality that passes informal review. That creates a confidence problem.
The model doesn’t know that a feature you’re describing is unavailable in Brazil due to regulatory constraints. It doesn’t know that your enterprise tier includes capabilities your consumer tier doesn’t. It doesn’t know that the term a competitor uses for a concept differs from yours, and that using it in your AI-generated content is a branding problem. None of this is in its training data. It can’t be. It’s proprietary, market-specific, and constantly changing.
Without that information, the model does what it’s designed to do: it fills the gap with its best approximation, drawn from billions of tokens of training data. That approximation is usually fluent. It is not always right.
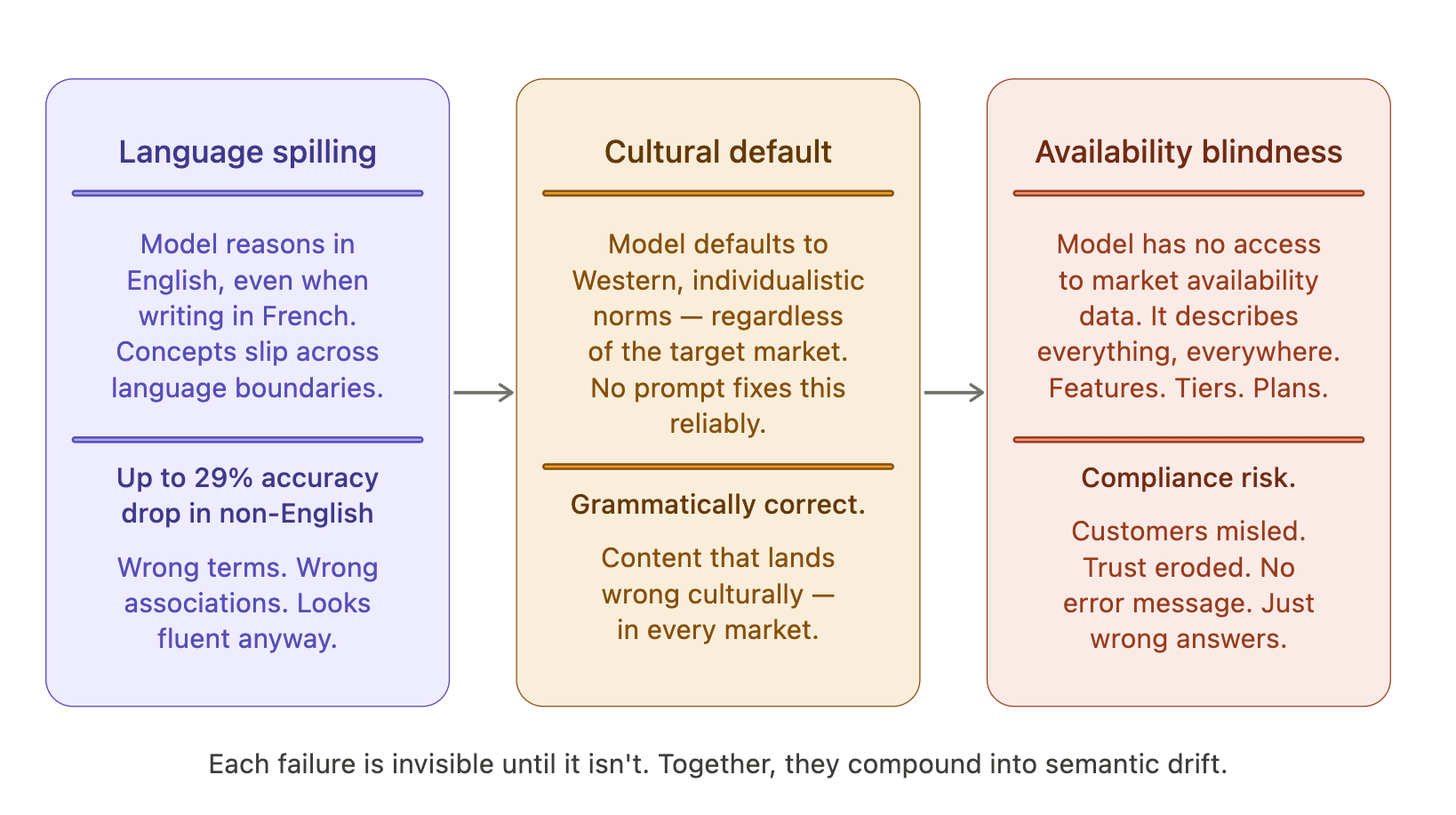
There’s also a structural issue that compounds this. Research has shown that multilingual LLMs tend to reason conceptually in English even when generating text in other languages, a phenomenon called language spilling. When asked to produce synonyms for a French word, the model may pull meaning from its English semantic space rather than French, producing output that is linguistically in French but conceptually contaminated by English associations. Even with advanced retrieval systems, accuracy drops of up to 29% in non-English languages compared to English have been documented.
For your business, that statistic means a system that performs reliably for English-language support queries may be quietly getting a quarter of the equivalent queries wrong in Spanish, German, or Japanese, and producing answers that look right to anyone without deep fluency in that language and domain.
The Cultural Layer Most Teams Miss
Linguistic accuracy is only half the problem. The other half is cultural, and it’s harder to address because it’s harder to see.
Research is consistent on this point: AI systems predominantly mirror the cultural values of Western, educated, individualistic societies, because that’s where most of the training data comes from. A model generating product descriptions without cultural calibration will default to a broadly American cultural frame regardless of the target market.
This produces content that is linguistically diverse but culturally homogeneous: content that reads as if it was written for a Western audience and then translated, even when it wasn’t.
The practical implications are real. In cultures that score high on what researchers call Uncertainty Avoidance — Germany and Japan among them — content that hedges with vague optimism and omits technical caveats reads as untrustworthy. In more collectivist markets, marketing content that emphasises personal achievement over team outcomes simply lands differently. These aren’t aesthetic preferences. They’re structural differences in how information is received and trusted.
You cannot reliably solve this through prompting alone. Telling a model to “write for a Japanese audience” produces some surface adjustment. It does not produce consistent, verifiable cultural alignment.
Here’s what it looks like when cultural knowledge is structural rather than prompted. The same questions, routed through a Black Ice ontology, for two markets:
The Framework: Semantic Governance
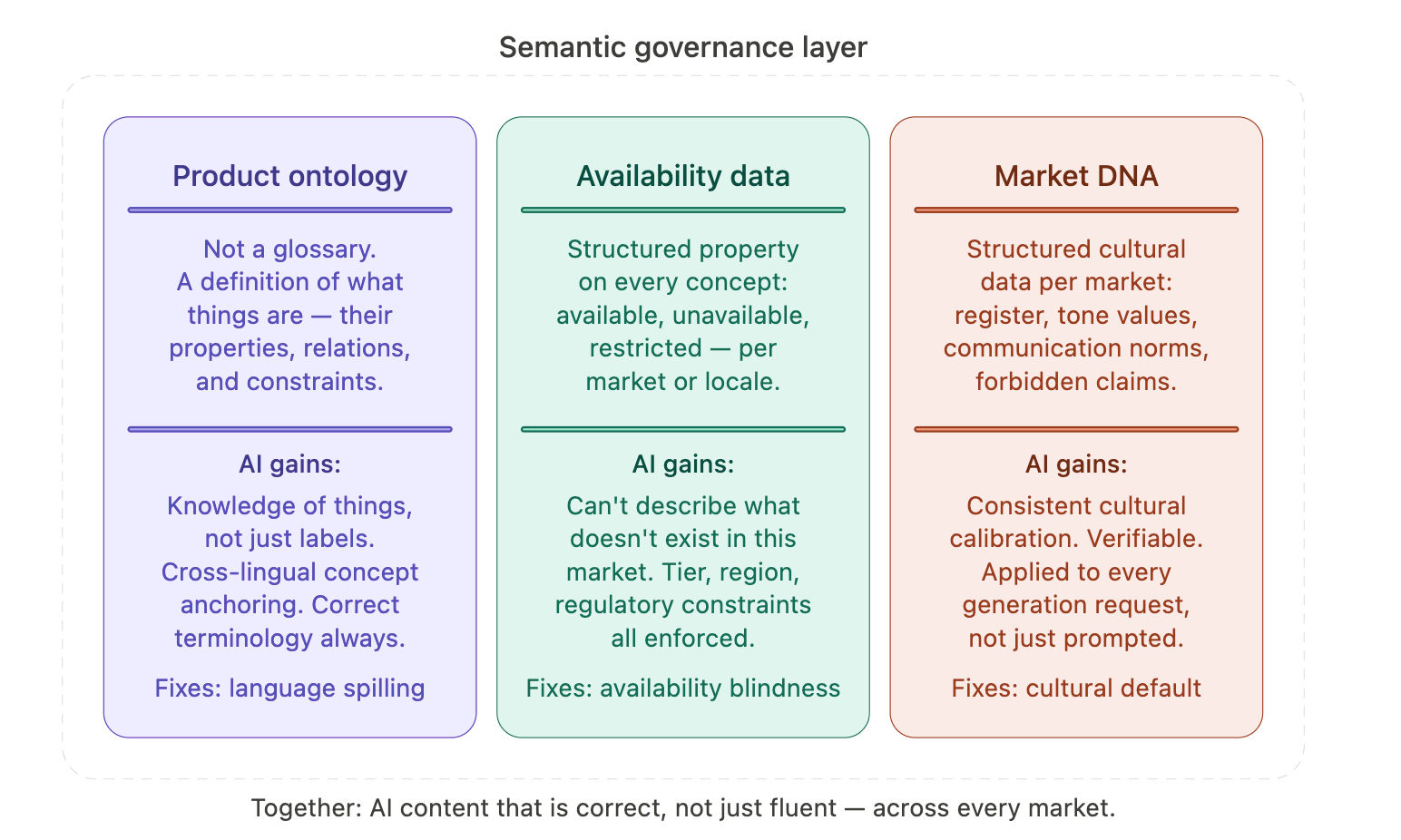
Semantic governance is the practice of making your product’s meaning explicit, and keeping it connected to the AI systems generating content about it.
Three components make it practical:
1. A multilingual product ontology
This is not a glossary. A glossary tells the model what to call things. An ontology tells the model what things are — their properties, their relationships to other concepts, and crucially, what can and cannot be said about them in each market.
The difference matters because AI systems don’t operate on surface-form substitution. They reason about concepts. A model given a glossary entry knows a word. A model given an ontology entry knows a thing — including that it’s unavailable in the EU, that it belongs to the enterprise tier only, and that it requires a specific legal disclaimer in three markets.

2. Market availability as structured data
What exists where is one of the most consistently neglected pieces of knowledge in AI pipelines. It needs to be encoded explicitly — not as a note in a document somewhere, but as a structured property attached to each product concept, available to the AI at the moment it generates content.
When a model has this information in context, it cannot describe an unavailable feature. When it doesn’t, it will, every time, because it has no reason not to.
3. A Market DNA definition
This is where cultural knowledge becomes operational. A Market DNA definition is structured data — not a style guide written for humans — that encodes the register conventions, tone values, communication norms, and explicit constraints for a specific market.
A high Uncertainty Avoidance score for Germany becomes a concrete instruction: precision over brevity, acknowledge limitations explicitly, avoid optimistic vagueness. A collectivist orientation for Japan becomes: emphasise organisational benefits over individual achievement. These travel with every generation request, applied consistently, verifiably.
The Questions to Ask Your Team This Week
Pull up one piece of AI-generated content from a non-English market. Ask:
Does this describe any feature that may not be available in this market?
Does this use our approved terminology, or something close to it?
Does the tone match how our customers in this market expect to be addressed?
If you can’t answer those questions confidently, not because the content looks wrong, but because you don’t have the infrastructure to check, that’s the gap semantic governance closes.
The Takeaway for Leaders
The fluency of modern AI creates a specific organisational risk: it makes problems invisible until they’re expensive. Semantic governance is the structural answer. Not a prompt, not a review checklist, but an architecture that keeps AI systems anchored to what your product actually is, in every market where it exists.
This is infrastructure work. It doesn’t produce flashy demos. What it produces is the difference between a multilingual AI system that generates content that looks right and one that is right. In markets where brand trust takes years to build and can be damaged in a single content release, that’s the only difference that matters.
I’ve spent the better part of a decade building this infrastructure inside large organisations and wishing a better version of it existed. That frustration became Black Ice. The thinking behind it lives at The AI-Ready Localizer — practical infrastructure for anyone governing multilingual AI seriously.
What to Remember

Thank you, Julia | Taking you global! Here she is articulating something I’ve been trying to say to executive coaching clients for a year and not finding the language for: fluent isn’t the same as accurate, and the markets you can’t audit are the ones paying the highest price for the difference.
If you’re running AI in markets you can’t read, the question isn’t whether you have a problem. It’s whether you have the infrastructure to find it. This is the same conversation I have with leaders building out the AI Leadership Triad. Adaptability and decision-making both fall apart fast when the system you’re leading produces output you can’t verify.
Subscribe to Julia at The AI-Ready Localizer for the structural side of this work. She’s the kind of practitioner I trust precisely because she sounds like an engineer, not a hype merchant.
Questions Leaders Are Asking
What is semantic governance in AI? Semantic governance is the practice of making a product’s meaning explicit and keeping that meaning connected to every AI system generating content about it. It has three structural pieces: a multilingual product ontology, structured market-availability data, and a Market DNA definition per region. Without it, multilingual AI sounds fluent and quietly produces wrong feature claims, off-brand terminology, and tone that misses the market.
Why does multilingual AI fail in non-English markets? Multilingual LLMs reason conceptually in English even when generating text in other languages, a pattern researchers call language spilling. Even with retrieval systems, accuracy drops of up to 29 percent in non-English queries are documented. The output reads fluent to non-native reviewers and can quietly contradict regulatory rules, market availability, or cultural register without anyone catching it for months.
What’s the difference between an AI glossary and an AI ontology? A glossary tells the model what to call things. An ontology tells the model what things are: their properties, their relationships to other concepts, and what can and can’t be said about them in each market. That difference is structural. AI systems don’t operate on surface-form substitution. They reason about concepts. A glossary patches the surface. An ontology fixes the reasoning.
Can prompt engineering solve multilingual AI accuracy? No, not on its own. Telling a model to “write for a Japanese audience” produces surface adjustments, not consistent, verifiable cultural alignment. (For more on why context beats prompts, see my piece on context engineering with Gemini.) Prompts vary across users and sessions. Structural infrastructure (ontology, market data, Market DNA) travels with every generation request and applies consistently.
How do I audit AI content in a language no one on my team reads? Start by encoding the things you can verify without language fluency: feature availability per market, approved terminology, and explicit “do not say” lists. These become structural checks the AI can be measured against, regardless of language. Once those are in place, sample translations for cultural register through a native reviewer or a structured Market DNA definition rather than informal review.
Is this only for enterprise companies? No. Any company shipping AI-generated content into more than one market faces this risk. Smaller teams feel it harder because they lack the in-house language coverage to spot quiet errors. Whether you build the ontology yourself, use a platform like Black Ice, or start with a simple structured market-availability table, the principle is the same: the AI needs to be told what your product actually is, per market.
Written by a human, for humans.
 | A guest post by
|
The insight for me here is that the LLM’s are based on language patterns, not thinking. And the language patterns are all originally in English. So that means the translation is going to be close, but just not quite there.
My native language is Italian, and somebody from the UK sent me a clip of them speaking Italian and it clearly was off
Build the infrastructure so your AI actually knows what your product is in each market. What a great idea!